Table of Contents
Scope/Description
- This article details the process of locating and replacing a failed storage drive/OSD in a Ceph Cluster.
Prerequisites
- SSH access to your Ceph Cluster
- Replacement Drive(s)
Steps
- First, we’ll have to figure out which drive has failed. We can do this through either the Ceph Dashboard or via the command line.
- In the Dashboard under the tab “Cluster > OSDs“, you can see which drives have failed. You will need the OSD number to physically locate the drive in the server.
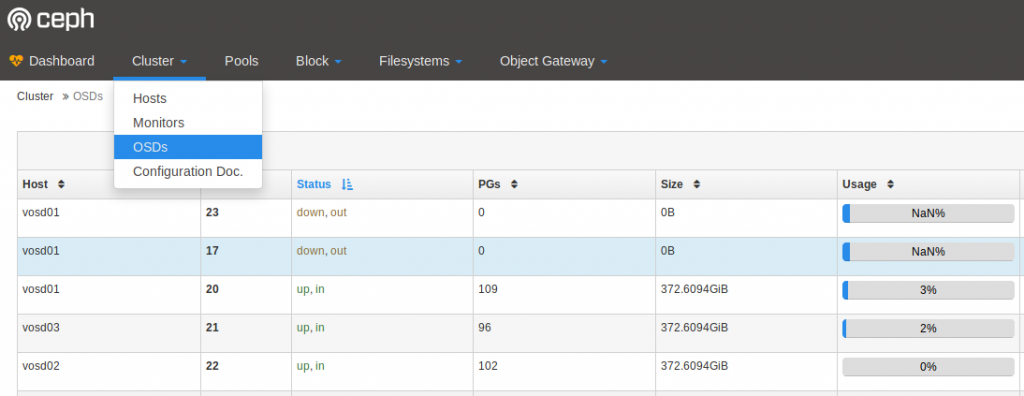
-
In the command line, run the ceph osd tree command in the terminal and look for OSD’s that are down or out.
ceph osd tree
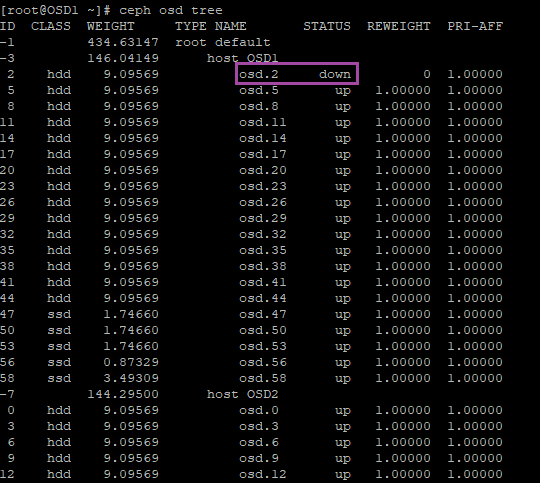
-
osd.2 is downed in the OSD tree above. It is located on host node OSD1.
- You will need to run the following command to physically find the downed OSD in the server. If you are running an older ceph cluster, see the troubleshooting section to locate the disk physically.
/opt/45drives/tools/findosd (#)

- Next. we’ll shrink the cluster by removing the failed OSD(s)
- SSH into the host(s) with failed OSD(s)
ssh osd1
If your OSD is not down and/or out, do the following before continuing:
systemctl stop ceph-osd@2
ceph osd out 2
-
Destroy the OSD(s)
ceph osd destroy 2 --yes-i-really-mean-it
- Purge the OSD(s)
ceph osd purge 2 --yes-i-really-mean-it
Do not remove failed OSD(s) from the Ceph Cluster until you have identified which drive it has been created on
-
Remove the failed disks physically from the system
-
Insert the new drive into the same slots. IF you use new slots take note of the name, use this new slot name below
-
Wipe the new disk if it has any data on it
ceph-volume lvm zap /dev/1-1
- Add the new OSD to the cluster
ceph-volume lvm create --data /dev/1-1
-
Observe data Migration
watch ceph -s
Verification
- When the data migration is done make sure the cluster is in a healthy state, and the amount of OSD’s in the cluster matches the amount previously in the cluster.
ceph -s
Troubleshooting
- For older clusters, you may not have the findosd tool. This is a way to find the physical location of a down osd.
-
In the dashboard, select failed OSD → Metadata. Look for the devices field.
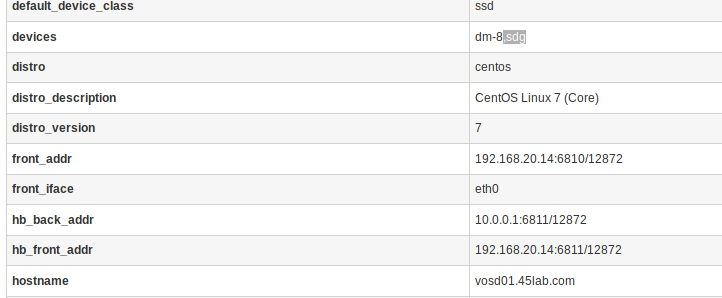
-
In the terminal:

ceph-volume lvm list
- Find the failed OSD. Read the device name.

-
osd.23=/dev/sdi and osd.17=/dev/sdg
Find Physical Location of Failed Devices
-
Remote into the host(s) with failed OSDs.
ssh root@vosd01
-
Map Linux device name to physical alias name.
ls -al /dev/ | grep sdg
lrwxrwxrwx. 1 root root 3 Jan 9 23:58 1-7 -> sdg brw-rw----. 1 root disk 8, 96 Jan 9 23:58 sdg
ls -al /dev/ | grep sdi
lrwxrwxrwx. 1 root root 3 Jan 9 23:58 1-6 -> sdi brw-rw----. 1 root disk 8, 128 Jan 9 23:58 sdi
-
OSD 17 is in slot 1-7 on host vosd01
-
OSD 23 is in slot 1-6 on host vosd01
Views: 2758