KB450156 - Replacing Failed Storage Drives in a Ceph Cluster
Posted on July 2, 2019 by Rob MacQueen

| 45Drives Knowledge Base |
KB450156 - Replacing Failed Storage Drives in a Ceph Cluster https://knowledgebase.45drives.com/kb/kb450156-replacing-failed-osds/ |
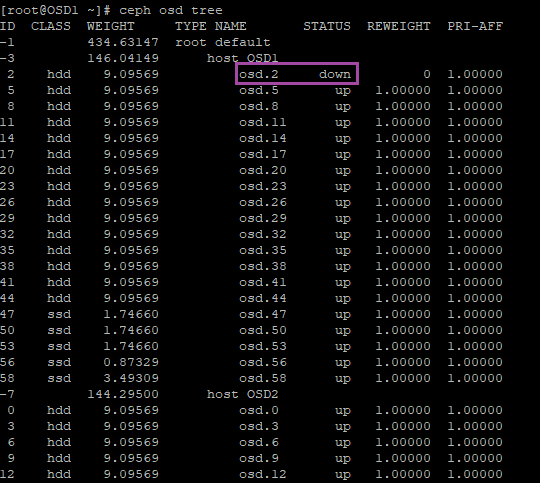
ceph osd tree
/opt/45drives/tools/findosd (#)

ssh osd1
systemctl stop ceph-osd@2
ceph osd out 2
ceph osd destroy 2 --yes-i-really-mean-it
ceph osd purge 2 --yes-i-really-mean-it
ceph-volume lvm zap /dev/1-1
ceph-volume lvm create --data /dev/1-1
watch ceph -s
ceph -s

ceph-volume lvm list

Find Physical Location of Failed Devices
ssh root@vosd01
ls -al /dev/ | grep sdg
lrwxrwxrwx. 1 root root 3 Jan 9 23:58 1-7 -> sdg brw-rw----. 1 root disk 8, 96 Jan 9 23:58 sdg
ls -al /dev/ | grep sdi
lrwxrwxrwx. 1 root root 3 Jan 9 23:58 1-6 -> sdi brw-rw----. 1 root disk 8, 128 Jan 9 23:58 sdi